mysql基于binlog回滚工具案例详细说明
时间:2022-6-10作者:未知来源:360教程人气:
- SQL是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持SQL。update、delete的条件写错甚至没有写,导致数据操作错误,需要恢复被误操作的行记录。这种情形,其实时有发生,可以选择用备份文件+binlog来恢复到测试环境,然后再做数据修复,但是这样其实需要耗费一定的时间跟资源。其实,如果binlog format为row,binlog文件中是会详细记录每一个事务涉及到操作,并把每一个事务影响到行记录均存储起来,能否给予binlog 文件来反解析数据库的行记录变动情况呢?业界已有不少相关的脚本及工具,但是随着MySQL版本的更新、binlog记录内容的变化以及需求不一致,大多数脚本不太适合个人目前的使用需求,所以开始着手编写 mysql的 flash back脚本。如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有。望各位支持!仅在MySQL 5.6/5.7版本测试,python运行环境需要安装pymysql模块。
1 实现内容
根据binlog文件,对某个\些事务、某段时间某些表、某段时间全库 做回滚操作,实现闪回功能。工具处理过程中,会把binlog中的事务修改的行记录存储到表格中去,通过 dml_sql 列,可以查看每一个事务内部的所有行记录变更情况,通过 undo_sql 查看回滚的SQL内容。如下图,然后再根据表格内容做回滚操作。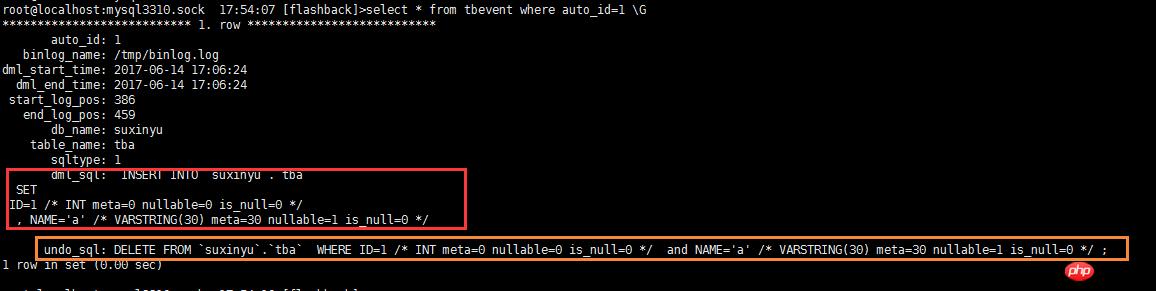 那么这个脚本有哪些优点呢?
那么这个脚本有哪些优点呢?回滚分为2个命令:第一个命令 分析binglog并存储进入数据库;第二个命令 执行回滚操作;
回滚的时候,可以把执行脚本跟回滚脚本统一存放到数据库中,可以查看 更新内容以及回滚内容;
根据存储的分析表格,方便指定事务或者指定表格来来恢复;
详细的日志输出,说明分析进度跟执行进度。
分析binlog的输出截图(分析1G的binlog文件) 回滚数据库的输出截图:
回滚数据库的输出截图:
2 原理
前提:实例启动了binlog并且格式为ROW。使用python对mysqlbinlog后的log文件进行文本分析处理,在整个处理过程中,有以下6个疑难点需要处理:判断一个事务的开始跟结束
同一个事务的执行顺序需要反序执行
解析回滚SQL
同一个事务操作不同表格处理
转义字符处理,比如换行符、tab符等等
timestamp数据类型参数值转换
负数处理
单个事务涉及到行修改SQL操作了 max_allow
针对某个表格做回滚,而不是全库回滚
2.1 事务的开始与结束
按照Xid出现的位置来判断,从binlog文件的最开始开始读取,遇到SQL语句则提取出来,直到遇到Xid,统一把之前提取出来的SQL汇总为一个事务,然后继续提取SQL语句,直到遇到下一个Xid,再把这个事务的SQL汇总成一个事务,一直这样循环,直至文件顺序遍历结束。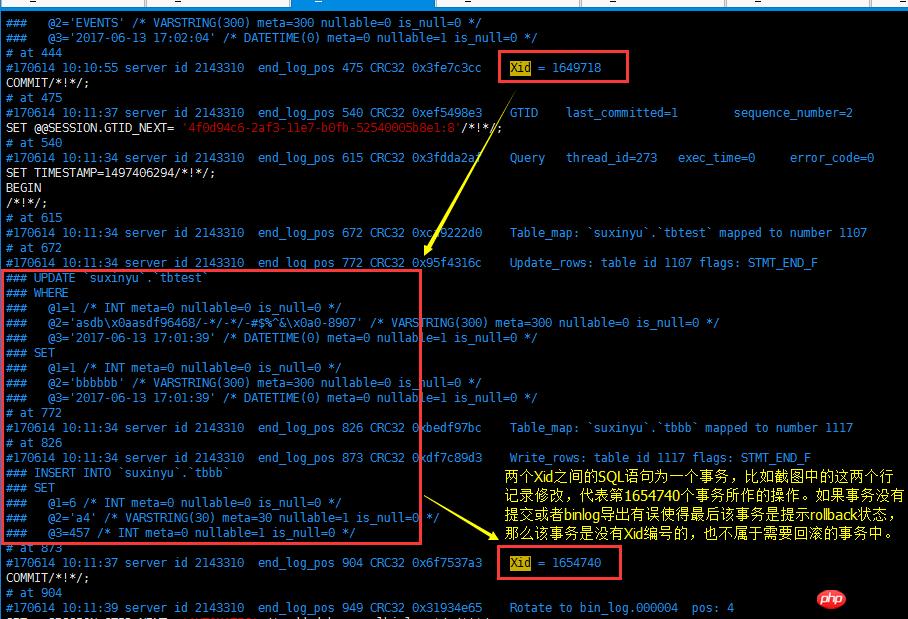
2.2 事务内部反序处理
同一个事务中,如果有多个表格多行记录发生变更,在回滚的时候,应该反序回滚SQL,那么,如何将提取出来的SQL反序存储呢?思路如下:每行记录的修改SQL独立出来
将独立出来的SQL反序存储
假设正序的事务SQL语句存储在变量 dml_sql 中,反序后的可以回滚的SQL存储在变量 undo_sql中。按顺序把行记录修改的SQL抽取出来 存储到变量 record_sql 中去,然后 赋值 undo_sql =record_sql + undo_sql ,再置空 record_sql 变量,如此,便可实现反序事务内部的执行SQL。2.3 解析回滚SQL
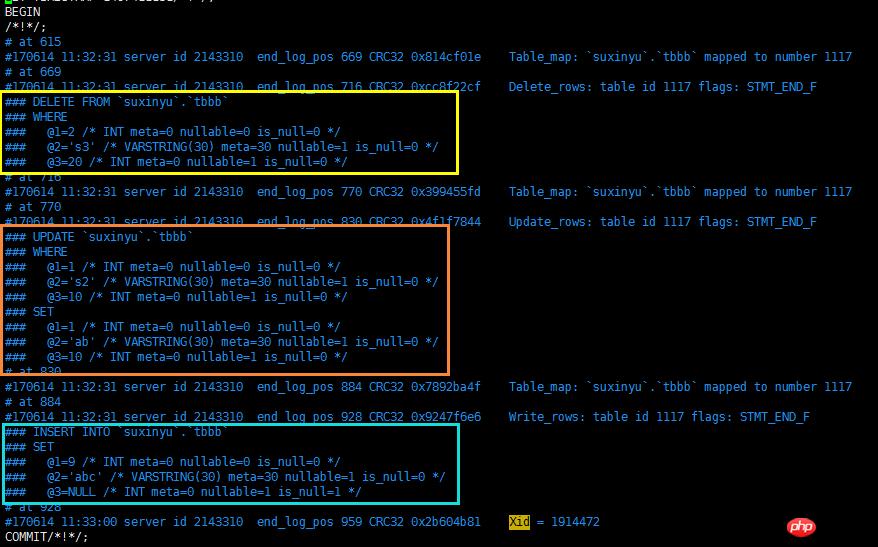
首先,查看binlog的日志内容,发现行修改的SQL情形如下,提取过程中需要注意这几个问题:行记录的列名配对,binlog file存储的列序号,不能直接使用
WHERE部分 跟 SET部分 之间并无关键字或者符号,需要添加 AND 或者 逗号
DELETE SQL 需要反转为 INSERT
UPDATE SQL 需要把WHERE 跟 SET的部分进行替换
INSERT SQL需要反转为 DELETE
2.4 同事务不同表格处理
同一个事务中,允许对不同表格进行数据修改,这点在列名替换列序号的时候,需要留意处理。每一个的行记录前有一行记录,含有 'Table_map' 标识,会说明这一行当行记录是修改哪个表格,可以根据这个提示,来替换binlog里边的列序号为列名。2.5 转义字符处理
binlog文件在对非空格的空白字符处理,采用转义字符字符串存储,比如,在表格insert一列记录含换行符,而实际上在binlog文件中,是使用了 \x0a 替换了 换行操作,所以在回滚数据的过程中,需要对转义字符做处理。
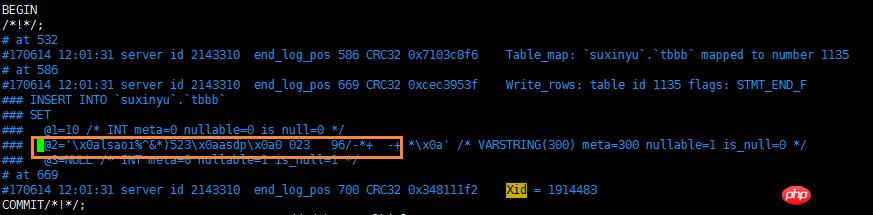 这里注意一个地方,039的转义字符是没有在函数 esc_code 中统一处理,而是单独做另外处理。
这里注意一个地方,039的转义字符是没有在函数 esc_code 中统一处理,而是单独做另外处理。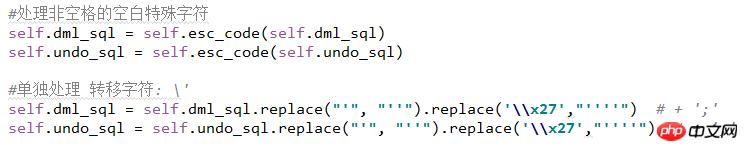 转移字符表相见下图:
转移字符表相见下图: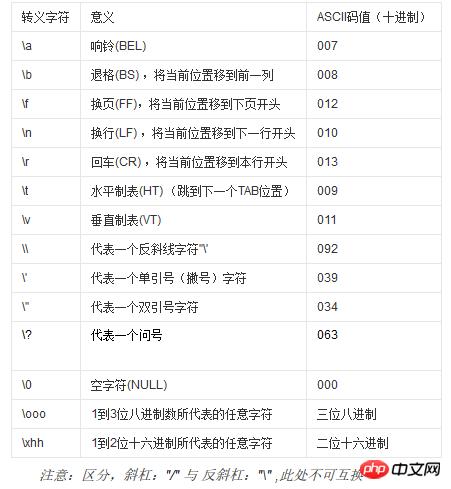
2.6 timestamp数据类型处理
timestamp实际在数据库中的存储值是 INT类型,需要使用 函数 from_unixtime转换。建立测试表格tbtest,只有一列timestamp的列,存储值后查看binlog的内容,具体截图如下: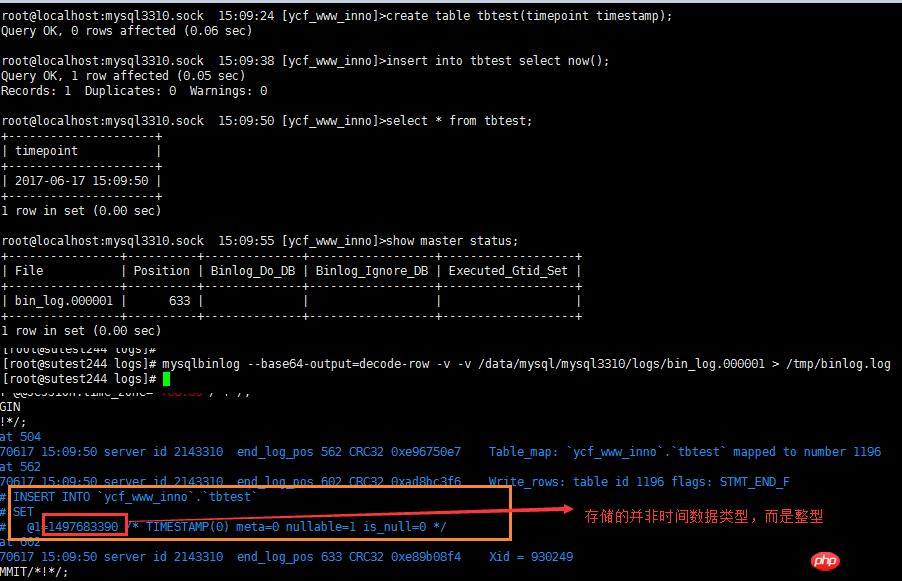 在处理行记录的时候,要对timestamp的value做处理,添加from_unixtime函数转换。
在处理行记录的时候,要对timestamp的value做处理,添加from_unixtime函数转换。2.7 负数值处理
这个一开始写代码的时候,并没有考虑到。大量测试的过程中发现,所有整型的数据类型,在存储负数的时候,都会存入一个最大范围值。binlog在处理这块的机制有些不是很了解。测试如下: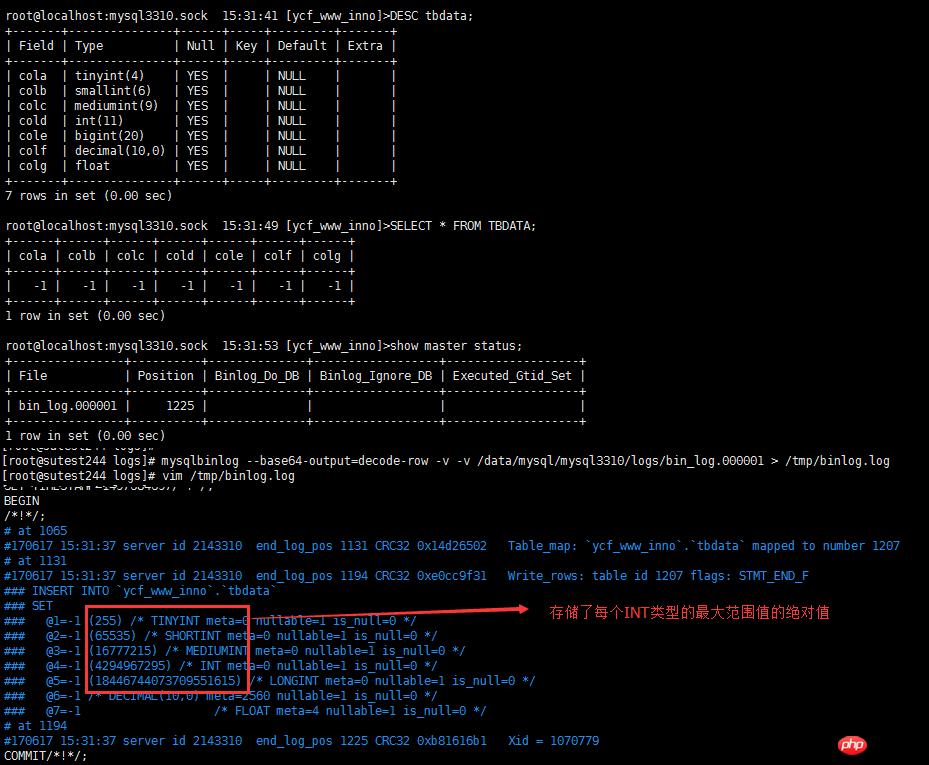 所以当遇到INT的各种数据类型并且VALUE为负数的时候,需要把 这个范围值去除,才能执行执行undo_sql。
所以当遇到INT的各种数据类型并且VALUE为负数的时候,需要把 这个范围值去除,才能执行执行undo_sql。2.8 单个事务行记录总SQL超过max_allowed_package处理
分析binlog后存储两种sql类型,一种是行记录的修改SQL,即 dml_sql;一种是 行记录的回滚sql,即 undo_sql。从代码可知,存储这两个sql的列是longtext,最大可存储4G的内容。但是 MySQL中单个会话的包大小是有限制的,限制的参数为 max_allowed_packet,默认大小为 4Mb,最大为1G,所以这个脚本使用前,请手动设置 存储binlog file的数据库实例以及线上的数据库实例这个参数:set global max_allowed_packet = 1073741824; #记得后续修改回来万一操作了呢?那么回滚只能分段来回滚,先回滚到 这个大事务,然后单独执行这个大事务,紧接着继续回滚,这部分不能使用pymysql嗲用source 文件执行,所以只能手动做这个操作。 求高能人士修改这个逻辑代码!!!2.9 针对性回滚
假设误操作的没有明确的时间点,只有一个区间,而这个区间还有其他的表格操作,那么这个时候,需要在分析binlog文件的时候,添加--database选项,先帅选到同一个数据库中binlog文件中。这里的处理是将这段区间的dml_sql跟undo_sql都存储到数据库表格中,然后再删除不需要回滚的事务,剩余需要回滚的事务。再执行回滚操作。3 使用说明
3.1 参数说明
这个脚本的参数稍微多些,可以 --help 查看具体说明。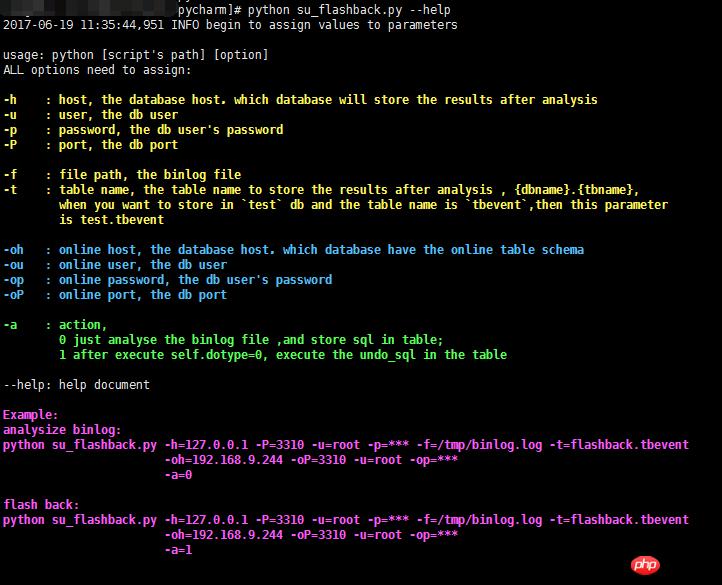 本人喜欢用各种颜色来分类参数(blingbling五颜六色,看着多有趣多精神),所以,按颜色来说明这些参数。
本人喜欢用各种颜色来分类参数(blingbling五颜六色,看着多有趣多精神),所以,按颜色来说明这些参数。黄色区域:这6个参数,提供的是 分析并存储binlog file的相关值,说明存储分析结果的数据库的链接方式、binlog文件的位置以及存储结果的表格名字;
蓝色区域:这4个参数,提供 与线上数据库表结构一致的DB实例连接方式,仅需跟线上一模一样的表结构,不一定需要是主从库;
绿色区域:最最重要的选项 -a,0代表仅分析binlog文件,1代表仅执行回滚操作,必须先执行0才可以执行1;
紫色区域:举例说明。
3.2 应用场景说明
全库回滚某段时间
需要回滚某个时间段的所有SQL操作,回滚到某一个时间点
这种情况下呢,大多数是使用备份文件+binlog解决
但是这个脚本也可以满足,但请勿直接在线上操作,先 -a=0,看下分析结果,是否符合,符合的话,停掉某个从库,再在从库上执行,最后开发业务接入检查是否恢复到指定时间点,数据是否正常。
某段时间某些表格回滚某些操作
比如,开发提交了一个批量更新脚本,各个测试层面验证没有问题,提交线上执行,但是执行后,发现有个业务漏测试,导致某些字段更新后影响到其他业务,现在需要紧急 把被批量更新的表格回滚到原先的行记录
这个并不能单纯从技术角度来处理,要综合考虑
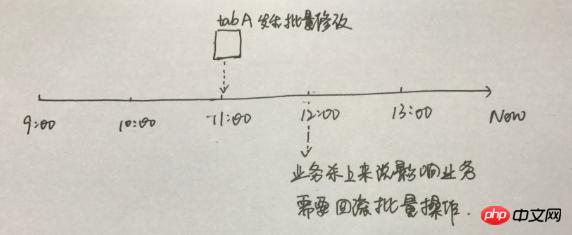
这种情况下,如何回顾tab A表格的修改操作呢?
个人觉得,这种方式比较行得通,dump tabA表格的数据到测试环境,然后再分析 binlog file 从11点-12点的undo sql,接着在测试环境回滚该表格到11点这个时刻,紧接着,由开发跟业务对比测试环境11点的数据跟线上现有的数据中,看下是哪些行哪些列需要在线上进行回滚,哪些是不需要的,然后开发再提交SQL脚本,再在线上执行。其实,这里边,DBA仅提供一个角色,就是把 表格 tab A 在一个新的环境上,回滚到某个时间点,但是不提供直接线上回滚SQL的处理。
回滚某个/些SQL
这种情况比较常见,某个update某个delete缺少where条件或者where条件执行错误
这种情况下,找到对应的事务,执行回滚即可,回滚流程请参考上面一说,对的,我就是这么胆小怕事

3.3 测试案例
3.3.1 全库回滚某段时间
假设需要回滚9点10分到9点15分间数据库的所有操作:准备测试环境实例存储分析后的数据
测试环境修改set global max_allowed_packet = 1073741824
mysqlbinlog分析binlog文件
python脚本分析文件,action=0
线上测试环境修改set global max_allowed_packet = 1073741824
回滚数据,action=1
线上测试环境修改set global max_allowed_packet = 4194304
1 --测试环境(请安装pymysql):IP: 192.168.9.242,PORT:3310 ,数据库:flashback,表格:tbevent 2 --具有线上表结构的db:IP:192.168.9.243 PORT:3310 3 4 5 mysql> show global variables like 'max_allowed_packet'; 6 +--------------------+----------+ 7
关键词:mysql基于binlog回滚工具案例详细说明